
If you’re running an eCommerce website, you’re probably familiar with the importance of SEO for driving traffic and sales. However, there’s one aspect of SEO that is often overlooked: robots.txt. This file plays a crucial role in controlling how search engine crawlers access and index your website’s content.
In this blog post, we’ll explore what robots.txt is, how it works, and why it’s essential for eCommerce SEO. We’ll also provide tips on how to optimise your robots.txt file for eCommerce, so you can maximise your visibility in search engine results pages (SERPs) and attract more customers. Whether you’re a seasoned eCommerce pro or just getting started, understanding robots.txt is essential for success in today’s digital landscape.
What is robots.txt?
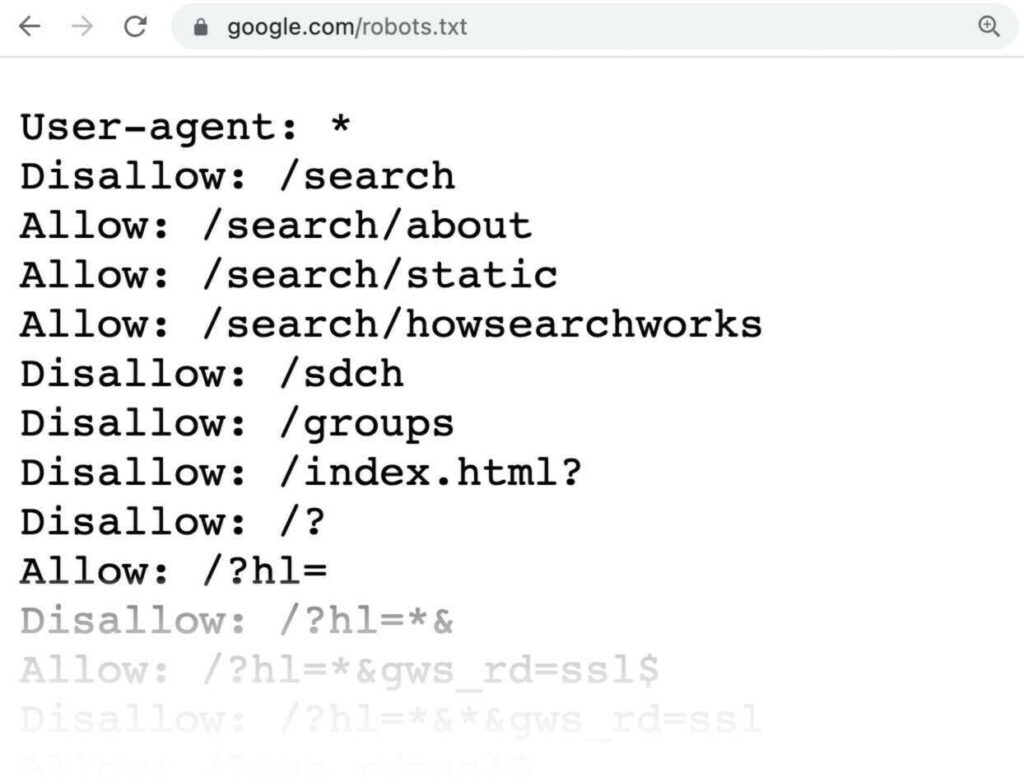
Robots.txt for eCommerce is a critical component of any technical SEO strategy. Placed in the root directory of a website, the robots.txt file instructs web crawlers which pages should be crawled and indexed. This file contains a list of directives that guide crawlers on which pages to avoid and which pages to crawl.
Using a standard format recognized by all major search engines, the robots.txt file can be used to address issues with duplicate content and wasted crawl budget, particularly for larger eCommerce sites. Ignoring these issues can have a critical effect on rankings and traffic, making it essential for eCommerce businesses to optimise their robots.txt file to maximize visibility and attract more customers.
Why robots.txt is Important for eCommerce Websites
When it comes to eCommerce websites, having a well-optimised robots.txt file can play a crucial role in improving search engine rankings and preventing duplicate content issues. With a large number of pages, including product pages, category pages, and search pages, eCommerce sites are particularly susceptible to these issues. By including a robots.txt file, eCommerce website owners can instruct search engine crawlers on which pages to crawl and which ones to avoid.
Furthermore, eCommerce websites may have pages that contain sensitive information, such as customer accounts and login pages. With a robots.txt file in place, website owners can ensure that these pages are not accessible to search engine crawlers or the general public, helping to protect customer information.
User Agents
User agents are pieces of software that act as clients on behalf of a user. In the context of web crawling, user agents identify the web crawler being used to access a website. Examples of bot user agents include Googlebot for Google, Bingbot for Bing, and Baiduspider for Baidu.
Website owners can use user agent directives in a robots.txt file to instruct specific web crawlers which pages to crawl and which pages to avoid. By doing so, they can prevent sensitive pages, such as customer accounts and login pages, from being publicly accessible.
User Agent Examples
Googlebot
Bingbot
DuckDuckBot
Baiduspider
YandexBot
Robots.txt Directives
Directives are the most common directives used in a robots.txt file. They are used to instruct specific search engine crawlers which pages to crawl and which pages to avoid.
Here is a list of all the directives that can be used in a robots.txt file:
User-agent: specifies the search engine crawler to which the following directives apply.
Disallow: instructs the search engine crawler not to crawl specific pages or directories on the website.
Allow: permits search engine crawlers to access specific pages or directories on the website that might be blocked by a preceding Disallow directive.
Crawl-delay: specifies the time delay (in seconds) that search engine crawlers should wait between successive requests to the website.
Sitemap: provides the URL of the sitemap file containing the list of all pages on the website that the search engine crawler should crawl.
Some of the most popular directives for eCommerce Websites
Disallow: /checkout/
Disallow: /cart/
Disallow: /account/
Disallow: /login/
Disallow: /register/
Disallow: /forgot-password/
Disallow: /reset-password/
Disallow: /*add-to-cart
These directives instruct web crawlers not to access URLs related to customer accounts and login credentials, as well as URLs that add products to the cart. These URLs may contain sensitive information that should not be publicly accessible.
Disallow: /?sort=
Disallow: /?limit=
These directives instruct web crawlers not to access any URLs that contain the “sort” or “limit” parameters, which are often used to display different sorting options and limit the number of products displayed on a page.
Disallow: /?q=
Disallow: /?search=
These directives instruct web crawlers not to access any URLs that contain the “q” or “search” parameters, which are often used to search for products or content on the website.
eCommerce URL Parameters
eCommerce websites often use various parameters in their URLs to track user behaviour and analytics data. However, these parameters can sometimes be indexed by search engines, leading to duplicate content issues and potentially harming the website’s search engine ranking. Here are some common directives for handling eCommerce parameters in a robots.txt file:
Disallow: /*?ref=
This directive instructs web crawlers not to access any URLs that contain the “ref” parameter, which is often used to track referral sources and may not be intended for public access.
Disallow: /*?page=
This directive instructs web crawlers not to access any URLs that contain the “page” parameter, which is often used to display different pages of products or content on the website.
Testing a robots.txt File
Testing a robots.txt file is important to ensure that it is working correctly and that search engine crawlers are following the directives. The easiest way to test a robots.txt file is to use Google Search Console. Here are the steps to test a robots.txt file using Google Search Console:
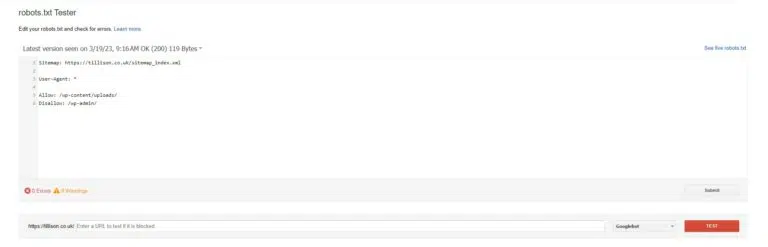
- Log in to Google Search Console and select your website property.
- Click on “Crawl” in the left-hand menu and select “robots.txt Tester”.
- Enter the URL of your robots.txt file in the box provided and click “Test”.
Google Search Console will show you whether the file is accessible or not and will display any errors or warnings that need to be fixed.
You can also use the “Live Test” feature to see how Google crawlers will interpret your robots.txt file.
Further Reading
If you found this blog post on robots.txt for eCommerce informative and useful, we have more articles that dive into this topic in greater detail for specific eCommerce platforms. Whether you’re using Shopify, WooCommerce, or another platform, our articles will provide you with valuable insights and tips to optimise your robots.txt file and improve your site’s SEO performance. Check out our blog for more eCommerce-related content, and stay tuned for more helpful tips and advice!
How To Update robots.txt In Shopify
How to Update robots.txt for WooCommerce
Conclusion
robots.txt for eCommerce websites is a crucial file that can benefit them in several ways. It can improve search engine rankings and prevent duplicate content issues.
Website owners can use user agent directives and eCommerce parameters in the file to instruct search engine crawlers on which pages to crawl and which ones to avoid.
Testing the robots.txt file using Google Search Console is vital to ensure that it is functioning correctly, and search engine crawlers are following the directives.
By following the best practices outlined in this article, eCommerce website owners can optimise their robots.txt file for search engine crawlers. This will help improve their website’s search engine ranking.
Thank you for taking the time to read this blog post on robots.txt for eCommerce. We hope you found it informative and helpful in optimising your site’s SEO performance.
If you have any questions or would like to learn more about how our eCommerce services can help your business grow, please don’t hesitate to drop a comment below or contact us directly.
At Tillison Consulting, our team of experts provide a variety of eCommerce services for a whole host of platforms through our eCommerce digital marketing agency, such as SEO for eCommerce, Google Shopping, CRO for eCommerce and many more.


